

コンピュータで文字が表示されるためには、文字に対応した「文字コード」が必要となる。コンピュータは、一つひとつの文字をコードで認識し、そこにフォント(字形)をかぶせることで、文字を表示することが可能になる。
文字コードはどのようにつくられているのか、そしてそこから何が見えるのか。文字コード研究の第一人者である京都大学人文科学研究所附属東アジア人文情報学研究センターの安岡孝一教授に伺った。
文字を「コード」(符号)によって表すことは、決してコンピュータの登場で始まったわけではない。たとえばひらがなは、50音順で並び方が決まっていて表の上に描くことができる。日本語話者にはお馴染みの、右端に「あ行」が並ぶ、あの「50音表」だ。この表に従い、50のひらがなをコードで表現することができる。「せ」であれば、表の右端から3列目、上端から4行目の場所にある文字として決まり、これを「34」などと表すことで、すべてのひらがなをコード化できる。つまり、文字を表に並べることはコード化のベースにあると言える。
このようなコードをコンピュータ上で表現するために、あらゆる文字について体系的に整理したものが「文字コード」だ。
まずはその歴史をざっとたどってみよう。
現在の文字コードのもっとも基礎となる部分を作ったのは、1963年にアメリカで制定された、英語や西欧諸国などで用いられる「ラテン文字」を中心とした「ASCII(American Standard Code for Information Interchange)」というコードである。コンピュータは、データを0か1かの2進数で扱い、その1ケタを「1ビット」と呼ぶ。ASCIIは、7ケタの2進数で表される7ビットのコードだ。7ビットで表現できる情報量は2の7乗(=128)個、そこに128種の文字を当てはめている。ASCIIに含まれるのは、アルファベットや数字、各種記号など、文章の読み書きに使用する文字や、コンピュータ制御用の特殊文字(制御文字)だ。
「同じラテン文字を使う言語でも、国や地域によって、通貨の記号やアクセント記号の有無などの違いがあります。たとえば、ドイツ語のウムラウトや、フランス語のセディーユ、スペイン語のティルデなどです。そのため、ASCIIをベースとし、その一部分をそれぞれの言語に適した記号に置き換えることで、その後、ヨーロッパの各言語に対応する文字コードがつくられていきました」
と、安岡教授は補足する。
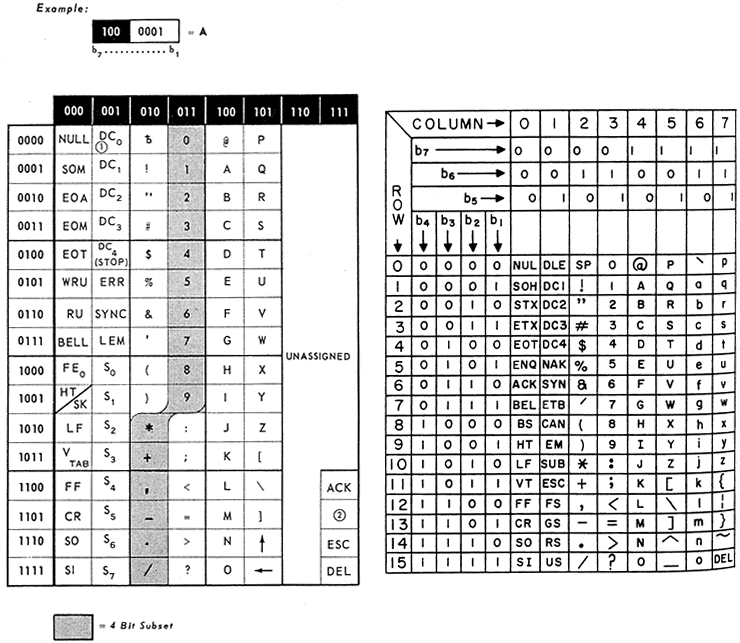
ASCIIの1963年版(左)と1967年版。各文字・記号のコードは、対応する列の3ケタの数字(63年版では上方の黒い枠内のもの、67年版では、”b7,b6,b5”と並べたもの)と行の4ケタの数字(63年版では左端の白い枠内のもの、67年版では、”b4,b3,b2,b1”と並べたもの)を順に並べてできる7ケタの2進数である。たとえばAは”1000001”。63年の制定時にはアルファベットの小文字は含まれていなかった。

気さくにかつ饒舌に話す安岡教授
では、ラテン文字とは全く異なる文字体系の日本はどうしたか。
「まず、ASCIIをベースに、カタカナと句読点をあわせておよそ60文字を表現可能な拡張文字コードをつくることにしました。7ビットのASCIIで表現可能な128の枠は、アルファベットや数字、制御文字にすべて割り当てられています。そこで、『8ビットコード(最大256文字)』の『JIS C 6220-1969』と呼ばれる文字コードが日本工業規格(JIS)によって1969年に制定されました。ビットを拡張することによって、表現できる文字数を増やしたのです」
だが、カタカナと句読点だけでは日本語を十分に表現することはできない。漢字やひらがなも表示するためには、桁違いに多くの文字を格納できる文字コードをつくる必要があった。
「そのために、1978年に制定されたのが『JIS C 6226』です。7ビットコードを2つ並べて最大9000文字近くが入るようにしたものです。128文字格納できる7ビットコードから、制御文字と空白に使うための34文字を除くと残りは94文字です。それを2つ並べると、94×94=8836文字を格納することができます」
その後、未収録の漢字を新たに追加するなどの改定作業が行われ、最新版の日本語文字コードは、2000年に制定されたJIS X 0213を2004年と2012年に改正した「JIS X 0213:2012」である。ここには、漢字、仮名文字、ラテン文字、数字、矢印などの記号を合わせて11233文字が収録されている。
このように、文字コードはまずは各国の事情に合わせて国や地域ごとに独自で作られていったが、ほどなく状況は変わっていく。安岡教授は言う。
「1980年代に入り、情報通信技術が発展し、国や地域をまたいで情報のやり取りが頻繁に行われるようになるにつれ、あらゆる言語を統一的に扱える国際的な文字コードの必要性が高まりました。そしてマイクロソフトやアップルといったアメリカ西海岸の企業を中心に作られたのが『Unicode(ユニコード)』です。それぞれの文字を使う国ごとの思惑もあり、複雑な経緯を経ながらも、90年代に入ってようやく形になりました」
Unicodeの名には、情報技術に関わる人々の理想が投影されている。「一つの(Uni)コード(code)」という名称が示すように、たったひとつの文字コードで、世界中の文字体系を表現することを目指して制定されたものなのだ。Unicodeはいまや、世界中で使われているさまざまな文字をできる限り集めた文字コードとして、コンピュータで標準的に使われる文字コードとなっている。
文字コードの研究は、安岡教授によれば大きく、人文科学的研究、情報科学的研究、社会科学的研究の3つに分けられるという。
「人文科学的研究とは、文字コードの歴史についての研究を指します。文字コードの歴史はいまなお明らかになっていないことが多く、それを解き明かすことには意味があると考えています。コンピュータが発展してきた流れとともに、国と国との思惑の違いをすり合わせながらコードができていく過程は、国際政治史をみるような面白さがあります。2つ目の情報科学的研究は、文字コードがコンピュータ上で正しく機能するためにコードの設計方法などについて考える仕事です。これは現状すでに、おおむね完了していると言えるでしょう」

文字コードについて、歴史から細部の数字まで生き字引のように詳しい。
上記の2つの研究分野ともに安岡教授は長く取り組んできたが、生きた文字コードを扱うという意味で、最も文字コードらしい研究は、残る社会科学的研究であるかもしれない。教授は言う。
「使われる文字は時代とともに変わるため、文字コードは常に“メンテナンス”が必要です。つまり、どの文字を新たに文字コードに追加するべきかを考える仕事が常にあります。これは、そのときどきの社会状況に関係するため、社会科学的な側面が強いと言えます。たとえば『常用漢字』を設計する人は、どの漢字を入れるべきかということをその時代の漢字の使われ方の状況から決めることになりますが、文字コードも同様にして追加すべき文字が考えられていくのです」
たとえば、90年代に制定されたJIS規格の文字コード(「JIS X 0208」や「JIS X 0212」)には、日本の地名に使われているのに収録されていない漢字があった。特定の地名以外にはほとんど使われない漢字のため、その地域の人以外は特に困ることはなくそのままにされていたのだ。だがそれではいけないということで、日本の地名で使われている文字は全部入れることになった。そうしてできたのが、2000年制定の「JIS X 0213」なのである。
安岡教授は、JIS X 0213の制定にもかかわってきた。「社会科学的研究」は、研究であるとともに実際に文字コードを作っていく実務的な側面も含まれると言えそうだ。

Unicode(ISO/IEO 10646)に収録されている文字一覧の一部(『JIS X 0221 国際符号化文字集合(UCS)』より)。漢字は、中国、台湾、日本、韓国、ベトナムで使われているものうち同じ字とみなせるものには、一つのコードが割り当てられている。2016年に制定されたUnicode 9.0.0(収録文字数128,172字)のコード表は、このような表で2500ページ近くにも及んでいる。
文字コードの研究は、日本国内のコードだけを扱うのであれば決してそれほど複雑ではないと安岡教授は語る。しかし、国家間の主張の違いを擦り合わせて「Unicode」ができていったように、文字コードはいまや一国だけの問題としては片づけられなくなっている。インターネットによって国境とは無関係に情報が行き来し、人的交流も国際化が飛躍的に進んだためである。
なかでも、文字数が膨大でかつ日本、中国、韓国、台湾、ベトナムといった国・地域の間で少しずつ形や使い方が異なる「漢字」を用いる私たちにとっては、文字コードについて考える際に、各国の施策が深く関係してくる。
「たとえば日本に住んでいる中国人が日本で子どもを産んだ場合を考えます。その際、中国の基準に沿った漢字を使って名前をつけたものの、それが日本の『常用漢字』にも『人名用漢字』(=日本の戸籍の子の名前として使える漢字のうち『常用漢字』に入っていないもの)にもない漢字だったら、どうやって日本の住民票に載せるかという問題が生じます。というのも、日本では子の名に使える漢字は、『常用漢字』と『人名用漢字』(と、ひらがな、カタカナ)のみと戸籍法で決められているためです。こうした問題を解決するため、日本では、在留カード、住民票に使える漢字というのを改めて定めたのですが、すべてを中国の基準に合わせるわけにはいかないため、そこにも入ってない漢字が名前に使われることも実際にはもちろんあるわけです」
住民票に使える文字をどのように規定するか。そこには国の施策があり、そのもとで、文字コードに新たにどの文字が追加されるべきかが決められていく。だが、情報だけでなく人の移動も容易に国境を跨ぐようになった今、日本の施策も、中国でどのような漢字が使われているかと無縁でいられなくなっているのだ。

常用漢字表(の一部)。2010年に改められ、現在2136字が収録されている。文化庁のウェブサイトより、表が取得できる。

人名用漢字表(の一部)。2010年の常用漢字の改定に伴って改められた。2015年に「巫」が加えられ、現在は合計862字。表は法務省のウェブサイトより。
たったひとつの文字コードで世界中の文字体系を表現するというUnicodeの理想は、完全に具現化しているとは言いがたい。
「たとえば韓国では、漢字は主に名前にだけ使われていて、現在、人名に使える漢字が8000字ほど決まっています。実はそのなかにUnicodeに入っていない漢字があり、その漢字が名前に入っている人は、日本に来ると自分の漢字が表示できず、各種手続きのときに困るという問題があります。韓国国内では韓国独自の文字コードを利用することで問題はないと思われますが、それゆえなのか、韓国側は、Unicodeにその漢字を入れてほしいという申請はしていません。その状態で、日本はどうすることもできません。このように、国の施策が理由で問題が解決しないという場合も少なからずあるのです」

センター所蔵文献のデジタルデータが入るコンピュータの管理も安岡教授が行っている。
2016年6月に発表されたUnicodeの収録文字数は128,172字に及び、2014年からの2年間だけでも15000字以上が新たに収録されている。いまだに、全世界にどれだけの文字が存在するかも分からず、絶えず変化もしていくことを考えると、上のような問題も避けられないのだろう。
「もはや変化のしようがないように見えるラテン文字でも、変化を続けています。たとえば、かつてソ連の一部だったバルト三国(エストニア、ラトビア、リトアニア)は、その時代はキリル文字を使っていましたが、ソ連崩壊後に各民族の言語が復権し、文字も、ラテン文字の上下に、他のどことも違うアクセント記号を付けたりするようになりました。つまり新しい文字が生まれたのです。漢字も、たとえば『高』と『髙』のように、時代の変化やその他さまざまな要因によって少しずつ変化しています。また、かつて使われていた歴史的な文字もUnicodeへの登録が進んでいるし、いまでは、日本の携帯電話で使われる絵文字(英語でもemojiと呼ばれる)も、Unicodeの中に多数含まれるようになっています」
たしかに、絵文字も多用されるのであれば文字コードが割り当てられた方が便利だろう(文字コードなしで画像として扱うことも可能だが、その場合、パソコンや携帯電話でのコピーができない)。しかし絵文字も文字として扱われるのであれば、もはや文字は無限に増えることになりうる。文字とはいったいなんなのかという問題にも思いが及ぶ。
「手書きの時代であれば、形が少し変化しようが、見る人がそれをこの文字だと認識できればそれで問題はありませんでした。しかしコンピュータが登場し、文字コードを使って表示させなければならなくなったために、そうした文字の“揺らぎ”のようなものをそのままでは扱えなくなった。変化したらその分だけ、文字コードを対応させていく作業が必要になったわけです。言語が変化していく以上、この仕事がいつまでも必要です。かつ、それをどうやって行っていくかを考えるのはとても興味深い仕事だと感じています」
文字コードをつくることは、単に文字をコードに置き換えるということではない。その作業を通じて、文字の果たす役割や、そもそも文字とは何かという本質的な問題を、私たちに気づかせてくれるのだ。

安岡教授の著作の一部。文字コードの歴史を扱った『文字符号の歴史』(安岡素子氏との共著)から、キーボード配列の謎に迫る『キーボード配列QWERTYの謎』(安岡素子氏との共著)など、文字コードを発端に広範なテーマを扱っている。
安岡教授の専門はもともと情報工学で、その流れで文字コードの研究を始めた。
「直接のきっかけは、京都大学の大型計算機センターに勤めていた1990年代にありました。一人の中国人留学生が、アメリカにいる中国人留学生から来たメールの文字が、日本のパソコンで文字化けしていると相談に来たのです。それは、送られてきたメールで使われていた文字コードが、日本のものとは全く異なる中国独自のものだったためでした。それなら、中国で使われている漢字の文字コードと日本の漢字の文字コードを対応させる仕組みをつくれば、大体の漢字は正しく表示されるはずだと考え、対応表をつくることにしたのです」
それを発端に、安岡教授は文字コードに関わるようになった。その後、2000年に漢字情報研究センター(現・東アジア人文情報学研究センター)の創設を機に、センター所蔵文献のデータベースを作ることを主なミッションとしてこのセンターに移ってきた。その仕事を通じても、文字コードとの関わりは深まっていった。

安岡教授が2005年に作成した「拓本データベース」にて「京」の文字を検索した結果の一部。これは京都大学人文科学研究所附属漢字情報研究センター(当時)所蔵の石刻拓本資料から、安岡教授らが各時代の石碑などに書かれた文字を切り抜き同じ文字ごとに集めデータベース化したもの。ある文字が時代とともにどのように変わってきたかが可視化できる。
そのころから、日本の文字コードの制定に、JIS策定委員として関わるようになるとともに、安岡教授は、文字コードやデータベースの専門家としてさまざまな仕事に取り組んできた。マイナンバー始動にあたってのシステムの構築や、キーボードがなぜ現在の「QWERTY」と呼ばれる配列になったかについての研究もある(マイナンバーやキーボード配列についての安岡教授の論文は、以下の安岡教授の個人ウェブサイトで読むことができる。)
「文字コードに関する仕事は、社会の変化と密接に関係しているところが面白さの一つです。国と国の関係など、研究で解決が付かないことがあるのは大変ですが、でもそれもまた面白い点ですね」
安岡教授のもとにやってくる学生のバックグラウンドはさまざまだという。文字コードは、文字を起点としてまさに幅広い世界につながっている。


東アジア研究に関するグローバルな研究拠点として、幅広い活動を行う。人文学と情報学を融合させた人文情報学的な手法を取り入れ、東アジアの史料・言語・文献・目録に関する研究情報を包括的に扱うシステムの研究開発を進めている。組織の母体は、1965年に創立された「東洋学文献センター」。創設趣旨は、東洋学に関する文献・資料を収集・整理して研究者の共同利用に供すること、および東洋学に関する学術情報活動を活発に行なうことにあった。その後、デジタル化の急速な進展に伴い、所蔵する漢字文献のデータベース化などを進めるために、2000年、「漢字情報研究センター」へ改組。さらに2009年、現センターへと改組した。
【取材・文:近藤雄生/撮影:吉田亮人】




 bana1.png (300px×80px)
bana1.png (300px×80px) bana1_e.png (300px×80px)
bana1_e.png (300px×80px) NovelPrize2015.png
NovelPrize2015.png